假设洛谷博客里面一共有 n(n≤10^5) 篇文章(编号为 1 到 n)以及 m(m<=10^6) 条参考文献引用关系。目前小 K 已经打开了编号为 1 的一篇文章,请帮助小 K 设计一种方法,使小 K 可以不重复、不遗漏的看完所有他能看到的文章。
这边是已经整理好的参考文献关系图,其中,文献 X → Y 表示文章 X 有参考文献 Y。不保证编号为 1 的文章没有被其他文章引用。
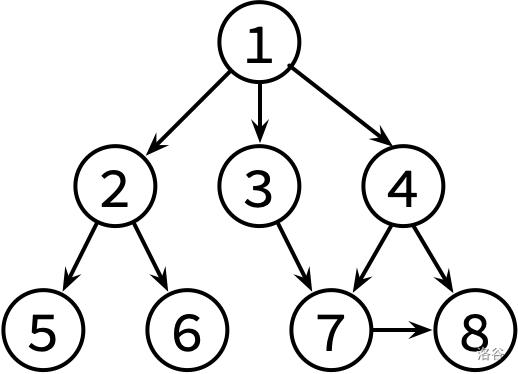
请对这个图分别进行 DFS 和 BFS,并输出遍历结果。如果有很多篇文章可以参阅,请先看编号较小的那篇(因此你可能需要先排序)。